
MR-IQA: A Unified Margin View of Regression and Ranking for Blind Image Quality Assessment
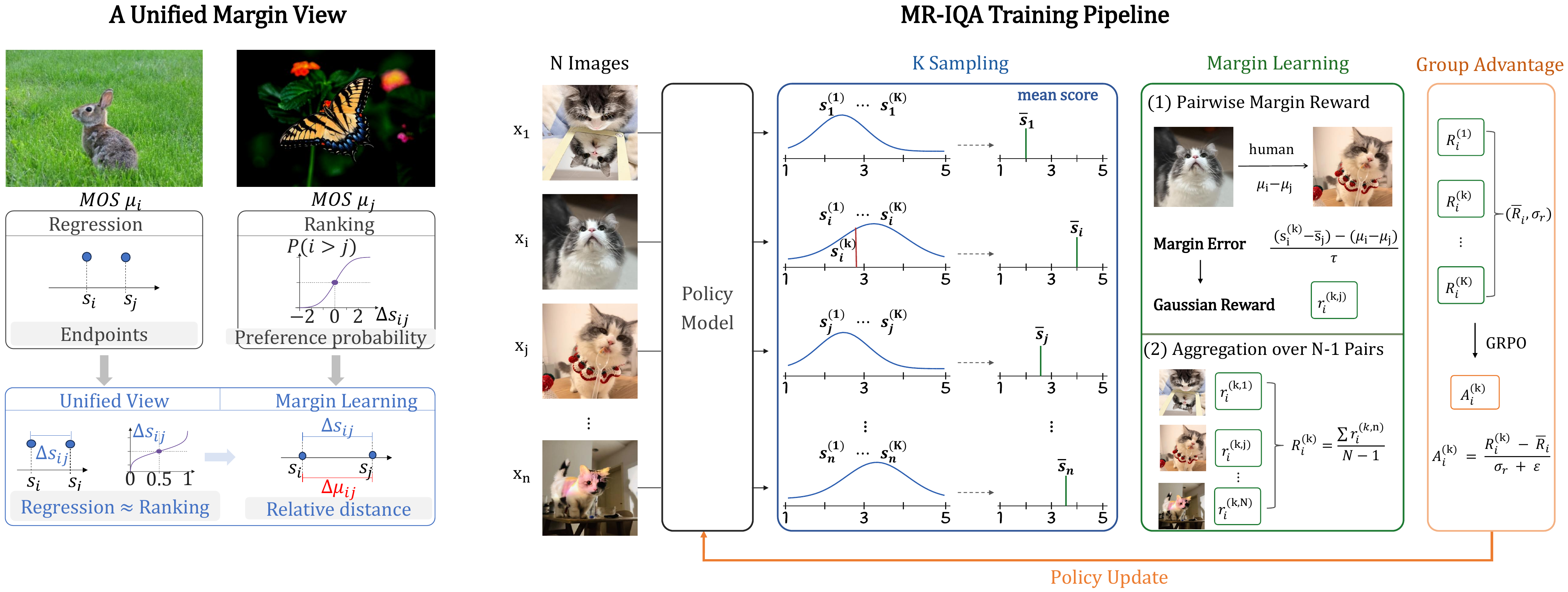
We derive that regression and ranking are approximately equivalent under a unified margin view. Based on this observation, we propose MR-IQA for margin learning in blind image quality assessment.
Validation Snapshot
The released checkpoint was validated after each epoch with an 8-shard setup on a held-out KONIQ split.
| Epoch | Valid samples | SRCC | PLCC | Shards |
|---|---|---|---|---|
| 1 | 200 | 0.8840 | 0.8894 | 8 |
| 2 | 200 | 0.9213 | 0.9302 | 8 |
| 3 | 200 | 0.9318 | 0.9392 | 8 |
| 4 | 200 | 0.9274 | 0.9340 | 8 |
| 5 | 200 | 0.9271 | 0.9409 | 8 |
| 6 | 200 | 0.9249 | 0.9406 | 8 |
| 7 | 200 | 0.9205 | 0.9408 | 8 |
| 8 | 200 | 0.9288 | 0.9465 | 8 |
| 9 | 200 | 0.9307 | 0.9450 | 8 |
| 10 | 200 | 0.9251 | 0.9421 | 8 |
Best SRCC was reached at epoch 3. The final released checkpoint corresponds to epoch 10. Sanitized training metadata is available in training_guidance/.
Quick Start
Load the model with a standard Transformers vision-language workflow. Provide one image and ask for an overall perceptual quality score in the 1 to 5 range. For easiest downstream parsing, request the final numeric score inside <answer>...</answer>.
Recommended prompt:
Assess the overall perceptual quality of this image. Briefly explain your assessment, then output a final quality score as a float between 1 and 5, rounded to two decimal places, inside
<answer>...</answer>.
Output Format
A typical response contains a short assessment followed by a final score:
The image has generally clear structure and acceptable perceptual quality, with some visible degradation in fine detail.
<answer>3.74</answer>
Citation
Citation information will be added with the accompanying paper release.
- Downloads last month
- -