
Omni2Sound
Collection
3 items • Updated
CVPR 2026 (Highlight)
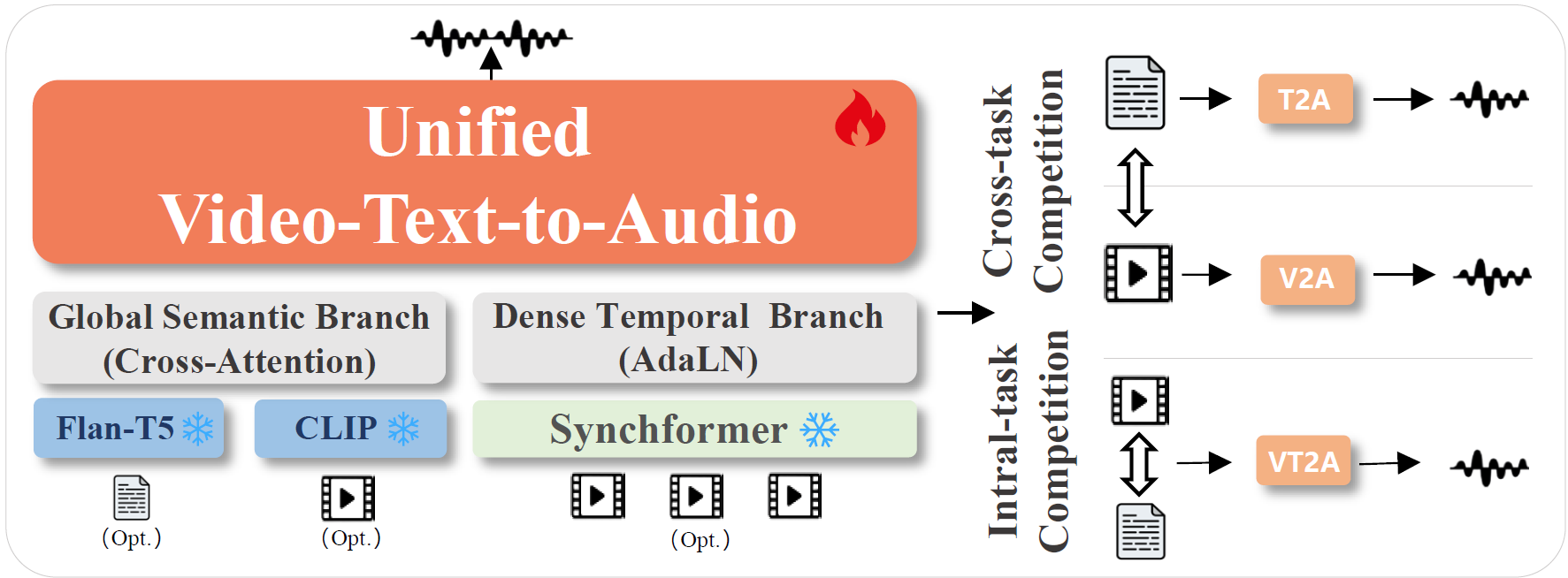
Omni2Sound is a unified framework for generating temporally aligned and semantically faithful audio from video, text, or both. A single model handles three tasks:
Omni2Sound achieves state-of-the-art performance across all three tasks on the VGGSound-Omni benchmark, surpassing both previous unified models (AudioX, MMAudio) and specialized models (ThinkSound, HunyuanVideo-Foley).
Omni2Sound is built on a standard Diffusion Transformer (DiT) backbone with a decoupled two-branch conditioning design:
The model is trained with a three-stage progressive multi-task training schedule:
omni2sound/
├── oob_vae_16k_224410.ckpt # Audio VAE
├── synchformer_state_dict.pth # Synchformer temporal encoder
└── vt2a-24-v55vt35-oa15-mq-td15/
├── args.yaml
├── data_config.yaml
├── model_config.json
└── checkpoints/model.ckpt # DiT backbone weights
Additionally, download the following dependencies into weights/:
| Model | Source |
|---|---|
| DFN5B-CLIP-ViT-H-14-384 | apple/DFN5B-CLIP-ViT-H-14-384 |
| flan-t5-base | google/flan-t5-base |
git clone https://github.com/omni2sound/Omni2Sound.git
cd Omni2Sound
pip install torch==2.1.0 torchaudio==2.1.0 torchvision==0.16.0 \
--index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
huggingface-cli download Dalision/Omni2Sound --local-dir weights/omni2sound
# Run inference
bash scripts/infer_online.sh
See the GitHub repo for full instructions on inference and finetuning.
@article{dai2026omni2sound,
title = {Omni2Sound: Towards Unified Video-Text-to-Audio Generation},
author = {Dai, Yusheng and Chen, Zehua and Jiang, Yuxuan and Gao, Baolong and
Ke, Qiuhong and Cai, Jianfei and Zhu, Jun},
journal = {arXiv preprint arXiv:2601.02731},
year = {2026}
}
Both the code and model weights are released under CC BY-NC 4.0 (non-commercial use only).