Sub-JEPA: Subspace Gaussian Regularization for Stable End-to-End World Models



Abstract
Joint-Embedding Predictive Architectures training is improved by applying Gaussian constraints in multiple random subspaces rather than the original embedding space, achieving better bias-variance balance and superior performance in continuous-control environments.
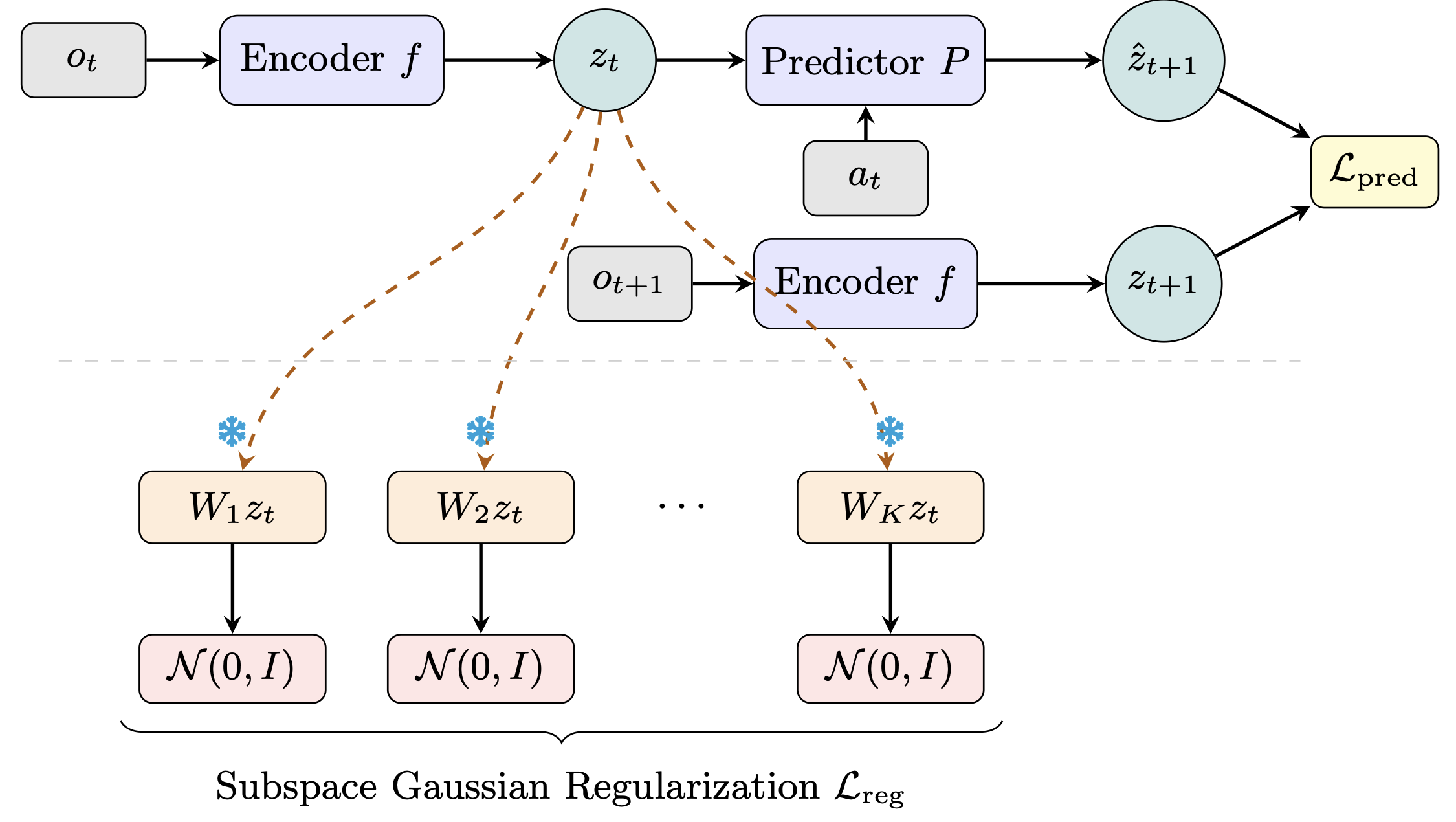
Joint-Embedding Predictive Architectures (JEPAs) provide a simpleframework for learning world models by predicting future latent representations.However, JEPA training is subject to a bias-variance tradeoff.Without sufficient structural constraints, excessive representationalvariance causes the model to collapse to trivial solutions.The recent LeWorldModel (LeWM) shows that this issue can be alleviated bysimply constraining latent embeddings with an isotropic Gaussian prior.However, latent representations inherently lie on low-dimensional manifoldswithin a high-dimensional ambient space, and enforcing an isotropic Gaussianprior directly in this ambient space introduces an overly strong bias.In this work, we propose ame, which seeks a favorable operatingpoint on the bias-variance frontier by applying Gaussian constraints inmultiple random subspaces rather than in the originalembedding space.This design relaxes the global constraint while preserving itsanti-collapse effect, leading to a better balance between trainingstability and representation flexibility.Extensive experiments across fourcontinuous-control environments demonstrate that consistentlyoutperforms LeWM with very clear margins.Our method is simple yet effective, and serves as a strong baseline for future JEPA-based world model research.fdefinedeeemodeThe code is available at https://github.com/intcomp/Sub-JEPA.
Community
We introduce Sub-JEPA, a simple improvement over LeWM for JEPA-based world models. LeWM prevents representation collapse by enforcing an isotropic Gaussian prior over the full latent space — but latent representations live on low-dimensional manifolds, making this constraint stronger than necessary.
Sub-JEPA instead projects latents into multiple random orthogonal subspaces and applies Gaussian regularization there. Same encoder, same predictor, better inductive bias.
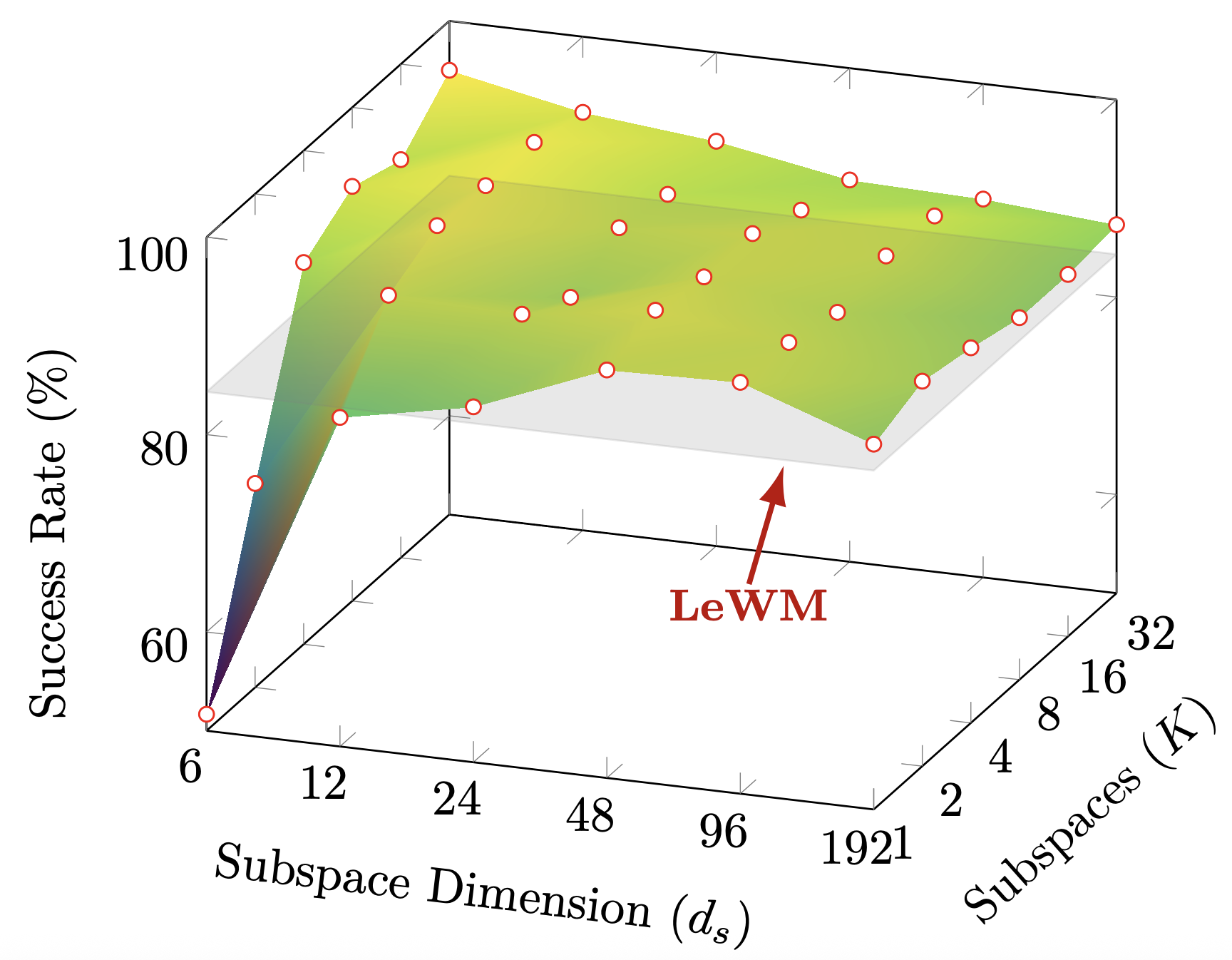
Consistent gains over LeWM across all 4 continuous-control benchmarks, with the largest improvements on low-intrinsic-dimensionality tasks.

Models citing this paper 1
Datasets citing this paper 0
No dataset linking this paper
Spaces citing this paper 0
No Space linking this paper
Collections including this paper 0
No Collection including this paper